Rows: 417
Columns: 15
$ Organization <chr> "Plex", "Twitter", "Shanghai Police", "City of Ama…
$ `Alternative Name` <chr> "", "", "", "", "", "", "", "", "", "", "", "", ""…
$ `Records Lost` <dbl> 15000000, 5400000, 500000000, 500000, 800000, 5000…
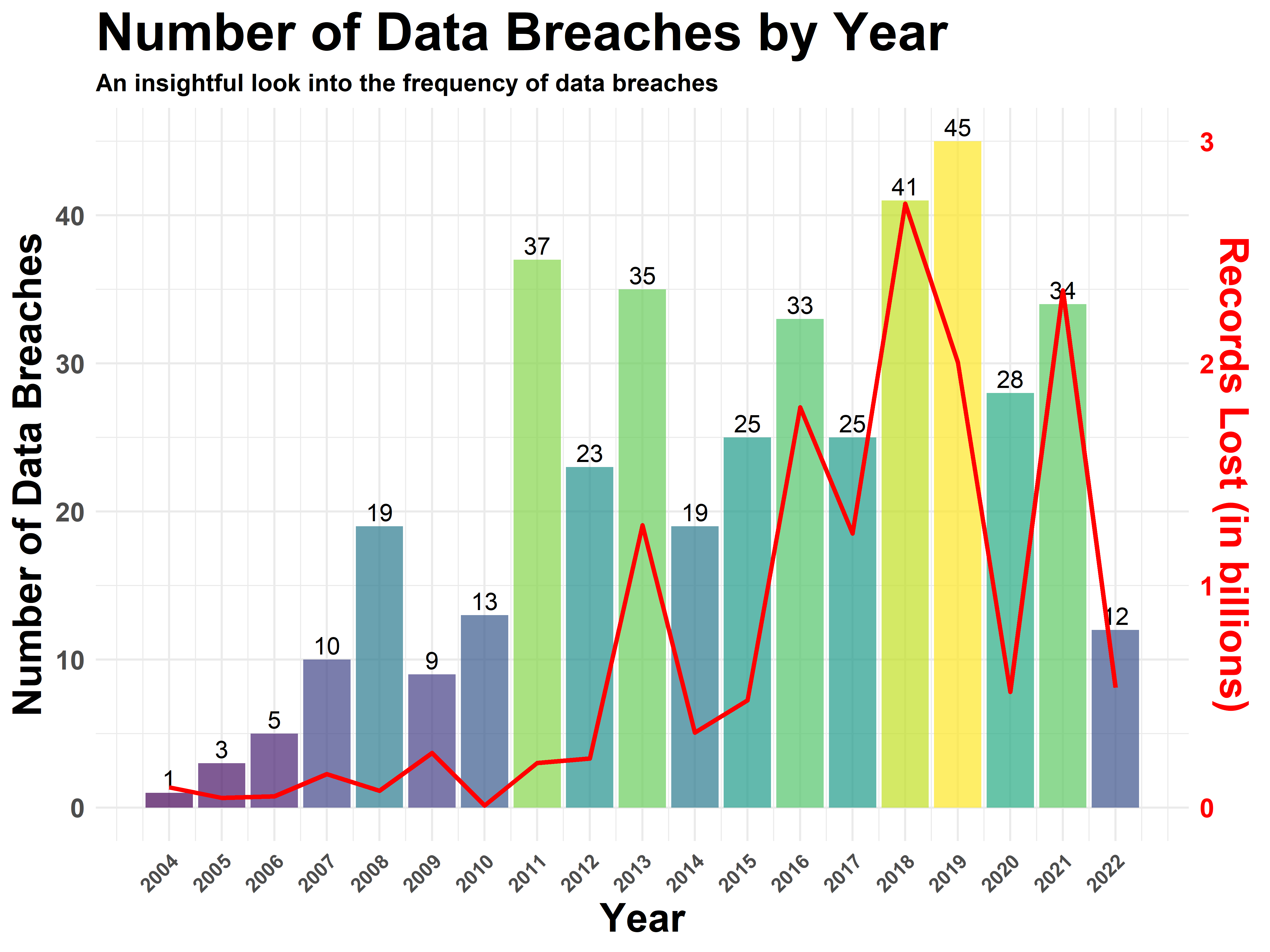
$ Year <dbl> 2022, 2021, 2022, 2022, 2022, 2022, 2022, 2022, 20…
$ Date <chr> "Aug 2022", "Dec 2021", "Jul 2022", "Jun 2022", "M…
$ Story <chr> "Intruders access password data, usernames, and em…
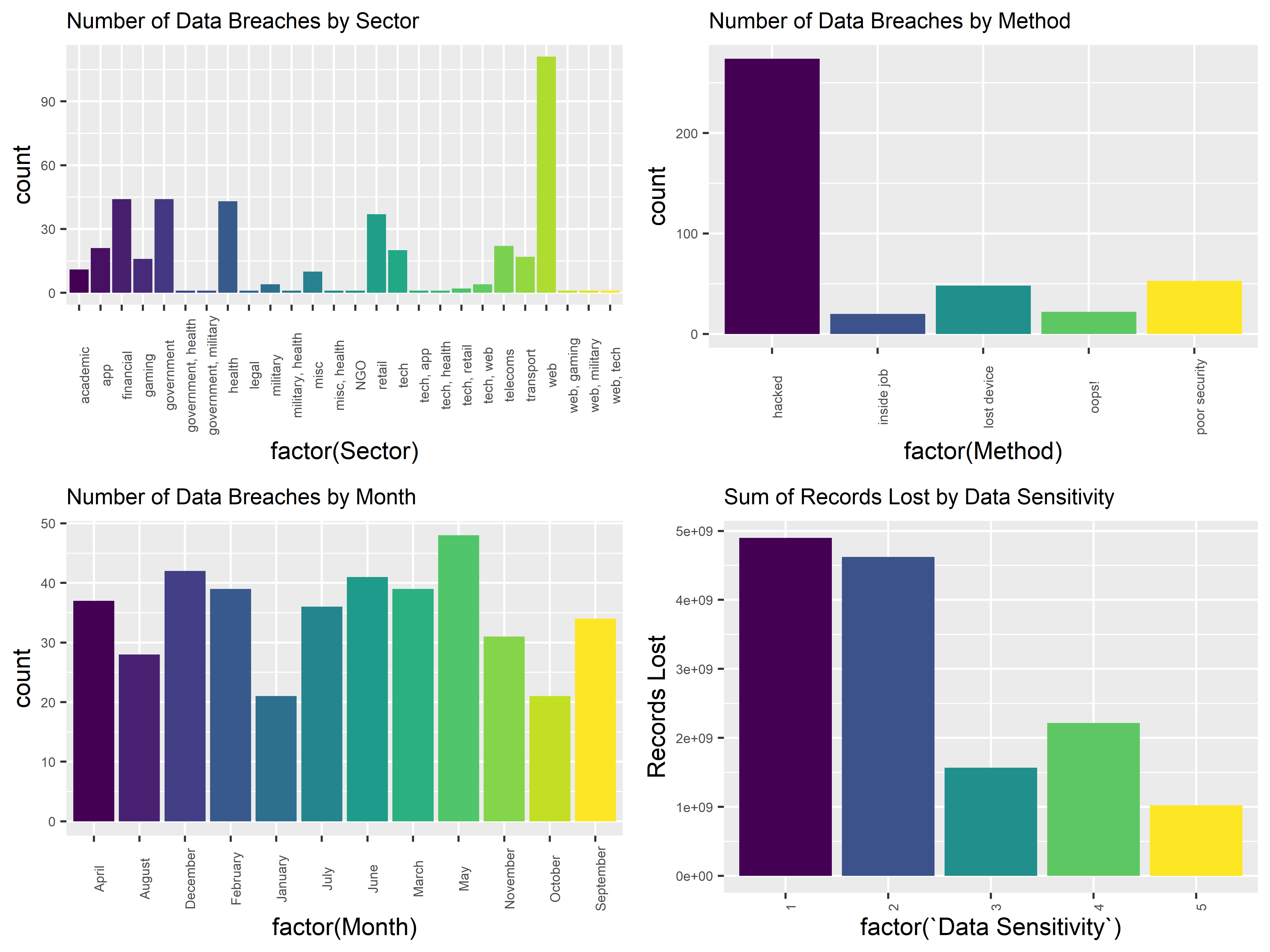
$ Sector <chr> "web", "web", "financial", "government", "financia…
$ Method <chr> "hacked", "hacked", "hacked", "oops!", "inside job…
$ `Interesting Story` <chr> "", "", "", "", "y", "", "", "", "", "", "", "", "…
$ `Data Sensitivity` <chr> "1", "2", "5", "3", "1", "2", "1", "3", "3", "3", …
$ `Displayed Records` <chr> "", "", "\"one billion\"", "", "", "", "", "", "19…
$ `Source Name` <chr> "Ars technica", "Bleeping Computer", "The Register…
$ `1st Source Link` <chr> "https://arstechnica.com/information-technology/20…
$ `2nd Source Link` <chr> "", "", "", "", "", "", "", "", "", "", "", "", ""…
$ ID <int> 418, 419, 420, 421, 417, 416, 415, 414, 413, 412, …